A surface light field represents the radiance of rays originating from any points on the surface in any directions. Traditional approaches require ultra-dense sampling to ensure the rendering quality. In this paper, we present a novel neural network based technique called deep surface light field or DSLF to use only moderate sampling for high fidelity rendering. DSLF automatically fills in the missing data by leveraging different sampling patterns across the vertices and at the same time eliminates redundancies due to the network’s prediction capability. For real data, we address the image registration problem as well as conduct texture-aware remeshing for aligning texture edges with vertices to avoid blurring. Comprehensive experiments show that DSLF can further achieve high data compression ratio while facilitating real-time rendering on the GPU.
Neural Renderer
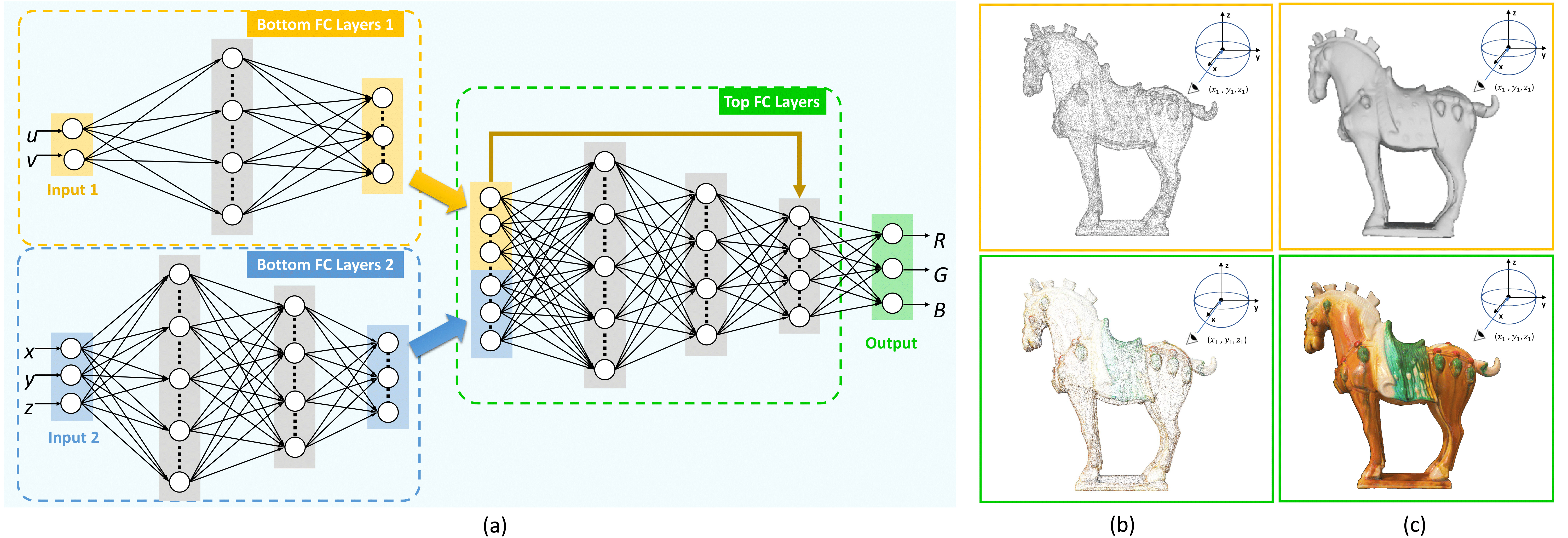
(a) Our deep surface light field (DSLF) network structure. The fully connected (FC) layers L1 and L2 subnets take ray coordinates as inputs and output to the FC T subnet, with an additional skip layer (yellow arrow). (b) shows a sample input(top) and per-vertex prediction(bottom). (c) shows the final output after rasterisation.
Result
We train our MVSNeRF with scenes of objects in the DTU dataset. Our network can effectively generalize across diverse scenes; even for a complex indoor scene, our network can reconstruct a neural radiance field from only three input images (a) and synthesize a realistic image from a novel viewpoint (b). While this result contains artifacts, it can be largely improved by fine-tuning our reconstruction on more images for only 6 min (c), which achieves better quality than the NeRF's nerf result (d) from 9.5h per-scene optimization.
Paper
