We present MVSNeRF, a novel neural rendering approach that can efficiently reconstruct neural radiance fields for view synthesis. Unlike prior works on neural radiance fields that consider per-scene optimization on densely captured images, we propose a generic deep neural network that can reconstruct radiance fields from only three nearby input views via fast network inference. Our approach leverages plane-swept cost volumes (widely used in multi-view stereo) for geometry-aware scene reasoning, and combines this with physically based volume rendering for neural radiance field reconstruction. We train our network on real objects in the DTU dataset, and test it on three different datasets to evaluate its effectiveness and generalizability. Our approach can generalize across scenes (even indoor scenes, completely different from our training scenes of objects) and generate realistic view synthesis results using only three input images, significantly outperforming concurrent works on generalizable radiance field reconstruction. Moreover, if dense images are captured, our estimated radiance field representation can be easily fine-tuned; this leads to fast per-scene reconstruction with higher rendering quality and substantially less optimization time than NeRF.
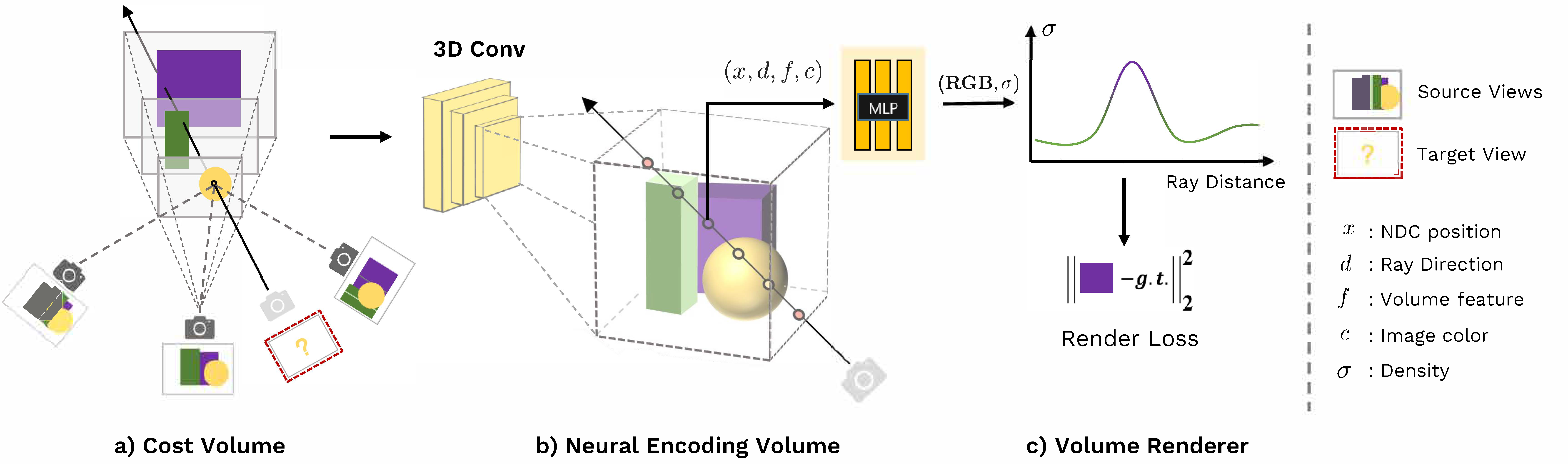
Pipeline
Our framework first constructs a cost volume (a) by warping 2D image features onto a plane sweep. We then apply 3D CNN to reconstruct a neural encoding volume with per-voxel neural features (b). We use an MLP to regress volume density and RGB radiance at an arbitrary location using features interpolated from the encoding volume. These volume properties are used by differentiable ray marching for final rendering (c).
Result

We train our MVSNeRF with scenes of objects in the DTU dataset. Our network can effectively generalize across diverse scenes; even for a complex indoor scene, our network can reconstruct a neural radiance field from only three input images (a) and synthesize a realistic image from a novel viewpoint (b). While this result contains artifacts, it can be largely improved by fine-tuning our reconstruction on more images for only 6 min (c), which achieves better quality than the NeRF's nerf result (d) from 9.5h per-scene optimization.
Results

Optimization progress. We show results of our fine-tuning (top) and optimizing a NeRF (bottom) with different time periods. Our 0-min result refers to the initial output from our network inference. Note that our 18-min results are already much better than the 215-min NeRF results. PSNRs of the image crops are shown in the figure.

Rendering quality comparison. On the left, we show rendering results of our method and concurrent neural rendering methods PixelNeRF, IBRNet by directly running the networks. We show our 15-min fine-tuning results and NeRF's 10.2h-optimization results on the right.
Paper
