Factor Fields
Factor Fields decomposes a signal into a product of factors, each represented by a classical or neural field representation which operates on transformed input coordinates. This decomposition results in a unified framework that accommodates several recent signal representations including NeRF, Plenoxels, EG3D, Instant- NGP, and TensoRF.
Factor Fields decomposes a signal into factors to , each of which is represented by one out of many different field representations (bottom-left) operating on coordinate transformations to . The resulting product field is passed to a projection function (e.g., MLP) which maps it to the signal’s output domain.
The above pipeline can be rewrited as the folling equation:
- \(\prod\) denotes the element-wise product of a sequence of factors
- each factor \(\mathbf{f}_i:\mathbb{R}^{F_i}\rightarrow\mathbb{R}^K\) is equipped with its own coordinate transformation \(\gamma_i:\mathbb{R}^D\rightarrow\mathbb{R}^{F_i}\)
- projection function \(\mathcal{P}\) maps the K-dimensional Hadamard product \(\prod_{i=1}^N \mathbf{f}_i\left(\mathbf{\gamma}_i(\mathbf{x})\right)\) to 𝑄-dimentional signal \(\mathbf{s}\).
Dictionary Fields (DiF)
Inspired by classical sparse coding and principal component analysis. We assume that signals are not random, but structured and hence share similar patterns within the same signal as well as between different signals. DiF decompose a signal into a basis field and a coefficient field. By leveraging periodic coordinate transformations, we can apply the same basis functions across various locations and scales.
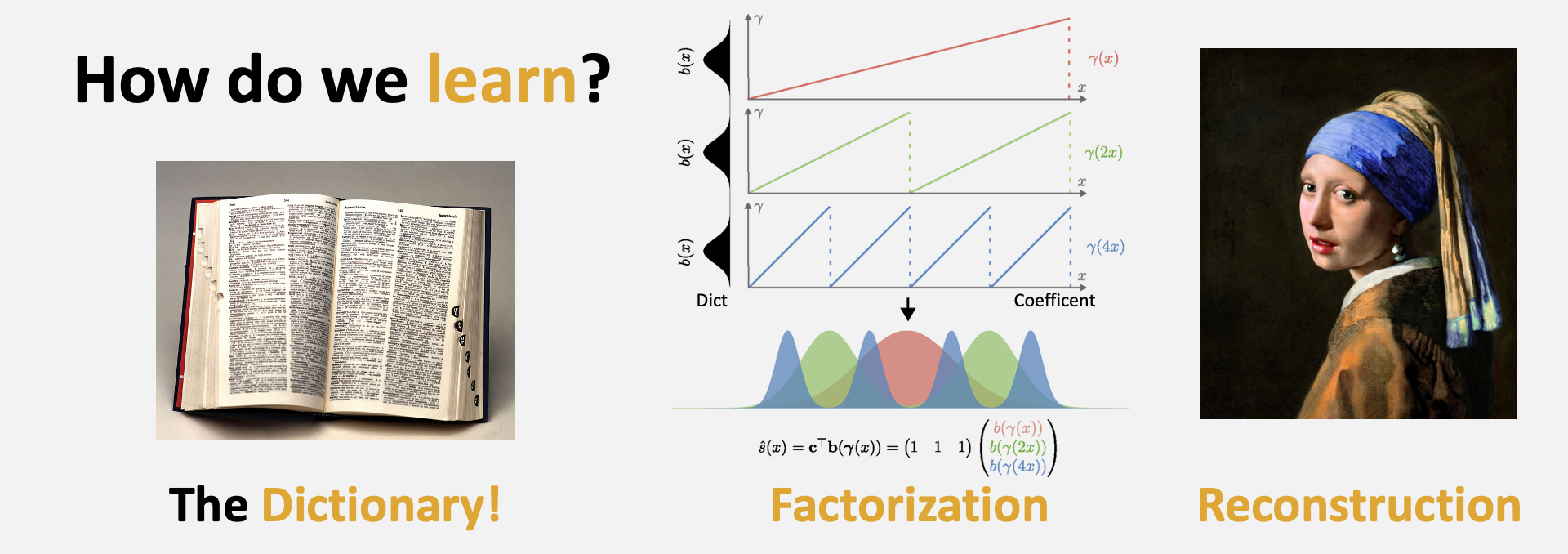
DiF is an instantiate of Factor Fields with Multi-Scale and Multi-Factor
Images
Input: All image pixels
Evaluation: PSNR on the whole image; Training time; Model parameters;
Our method achieves better reconstruction quality on all images when using the same model size. While optimization is slower than Instant-NGP, we use a vanilla PyTorch implementation without customized CUDA kernels. “Summer Day” credit goes to Johan Hendrik Weissenbruch and rijksmuseum. “Albert” credit goes to Orren Jack Turner. “Pluto” credit goes to NASA. “Girl With a Pearl Earring” renovation ©Koorosh Orooj (CC BY-SA 4.0).
SDFs
Input: 8M SDF points sampled from the target meshes for training, with 80% points
near the surface and the remaining 20% points uniformly distributed inside the unit volume
Evaluation: We randomly sample 16M points for evaluation and calculate
the geometric IOU metric based on the SDF sign; Training time;
We show qualitative visual comparisons on the top and quantitative comparisons on the bottom including the number of parameters, reconstruction time, gIoU, and chamfer distance (CD). DiF-Grid and Instant-NGP [Müller et al. 2022] are trained for 10𝑘 iterations, while SIREN [Sitzmann et al. 2020] and NeRF with Frequency Position Encoding (PE) [Tancik et al. 2020] are trained for 200𝑘 iterations.
NeRF
Input: Multi-view images
Evaluation: PSNR/SSIM on novel views; Training time;
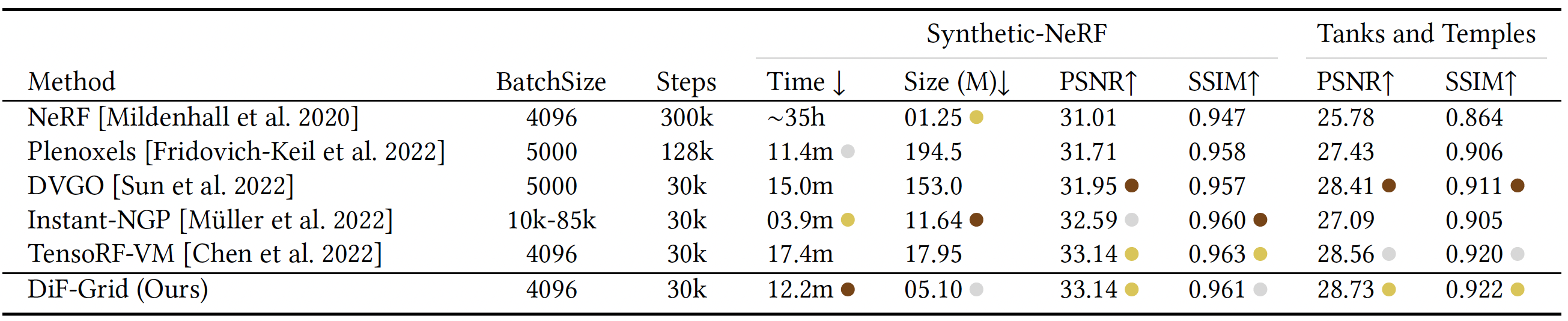
Our method achieves high reconstruction quality, significantly outperforming NeRF, Plenoxels, and DVGO on both datasets, while being significantly more compact than Plenoxels and DVGO. We also outperform Instant-NGP and are on par with TensoRF regarding reconstruction quality, while being highly compact with only 5.1M parameters, less than onethird of TensoRF-VM and one-half of Instant-NGP. Our DiF-Grid also optimizes faster than TensoRF, at slightly over 10 minutes, in addition to our superior compactness. Additionally, unlike Plenoxels and Instant-NGP which rely on their own CUDA framework for fast reconstruction, our implementation uses the standard PyTorch framework, making it easily extendable to other tasks.
Inpainting
Input: Masked image pixels
Evaluation: Visualization effect only since there's no gt in inpainting task;

We show the image regression results on three different facial images with various masks and compare them to baseline methods that do not use any data priors, including Instant-NGP and our DiF-MLP-B without pre-training. As expected, Instant-NGP can accurately approximate the training pixels but results in random noise in the untrained mask regions. Interestingly, even without pre-training and priors from other images, our DiF-MLP-B is able to capture structural information to some extent within the same image being optimized; as shown in the eye region, the model can learn the pupil shape from the right eye and regress the left eye (masked during training) by reusing the learned structures in the shared basis functions. As shown above, our DiF-MLP-B with pre-trained prior clearly achieves the best reconstruction quality with better structures and boundary smoothness compared to the baselines, demonstrating that our factorized DiF model allows for learning and transferring useful prior information from the training set.
Few-Shot NeRF
Input: 3 or 5 neighboring views, the generalization models we are trained on 100 Google Scanned Object scenes [Downs et al. 2022]
Evaluation: PSNR/SSIM on novel views; Training time;
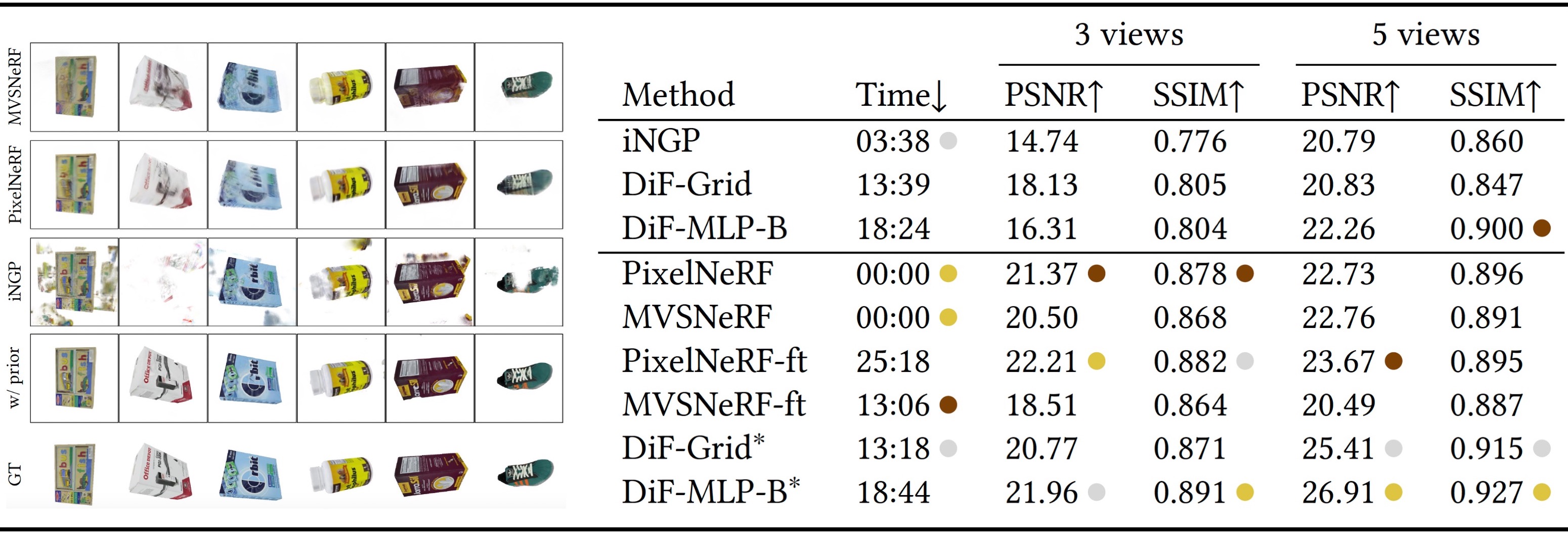
Our pre-trained DiF representation with MLP basis provides strong regularization for few-shot reconstruction, resulting in fewer artifacts and better reconstruction quality than the single-scene optimization methods without data priors and previous few-shot reconstruction methods that also use pre-trained networks. In particular, without any data priors, single-scene optimization methods (Instant-NGP and ours w/o prior) lead to a lot of outliers due to overfitting to the few-shot input images. Previous methods like MVSNeRF and PixelNeRF achieve plausible reconstructions due to their learned feed-forward prediction which avoids per-scene optimization. However, they suffer from blurry artifacts. Additionally, the strategy taken by PixelNeRF and MVSNeRF assumes a narrow baseline and learns correspondences across views for generalization via feature averaging or cost volume modeling which does not work as effectively in a wide baseline setup. On the other hand, by pre-training shared basis fields on multiple signals, our DiF model can learn useful data priors, enabling the reconstruction of novel signals from sparse observations via optimization.
We would like to thank Bozidar Antic, Zehao Yu, Hansheng Chen, Shaofei Wang for helpful discussion and suggestions. This work was supported by the SNF grant 200021, 204840.
This project page includes two papers:
- Dictionary Fields: Learning a Neural Basis Decomposition
- Factor Fields: A Unified Framework for Neural Fields and Beyond
Please cite us if you find our work useful: